SyncMos: Scalable Motion Synchronisation
for Multi-Agent Scene Interaction
Abstract
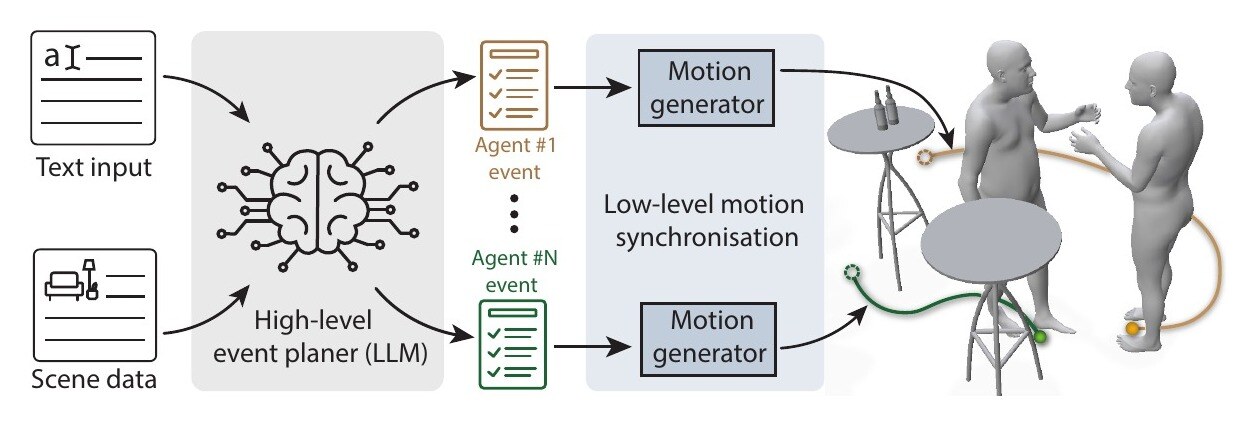
Text-guided motion generation in 3D scenes has advanced the synthesis of human–scene interactions, contributing to embodied AI, scene understanding, and virtual agent simulation. While recent studies have begun exploring multi-agent scenarios, achieving temporally synchronised interactions among multiple agents remains an open challenge. Existing methods are often limited in flexibility and scalability when handling diverse interaction contexts.
We present a method that enables synchronised multi-agent interaction using a single-agent motion synthesis model through two key components: a text-guided dependency-aware story planner and a temporal synchronisation module. The story planner interprets natural language instructions into structured event sequences with temporal dependencies. Our synchronisation module, built upon time-warping control and diffusion posterior sampling, aligns interaction timing across agents without retraining.
Experimental results demonstrate that the proposed framework effectively models temporal dependencies and causal order between events. Evaluations across diverse interaction types show improved temporal alignment and coherent multi-agent motion generation consistent with textual instructions.
Qualitative Results
Low-level motion synchronisation module
Yellow: Original (LINGO) · Pink: Our method
Timing control
Pick up the bottle.

1 s slower than the initial estimate.

1 s faster than the initial estimate.
Handover
Left person gives the object to the right person.

Not matched

Synced
SyncMos (full framework)
Sequential handover
Across scenes and agent counts. Left: Event-Driven Storytelling + LINGO · Right: Ours.

3 agents — House

3 agents — Restaurant
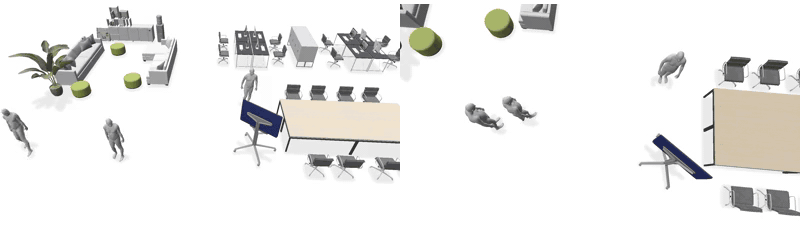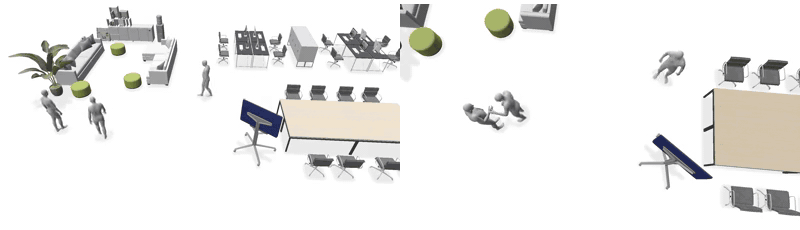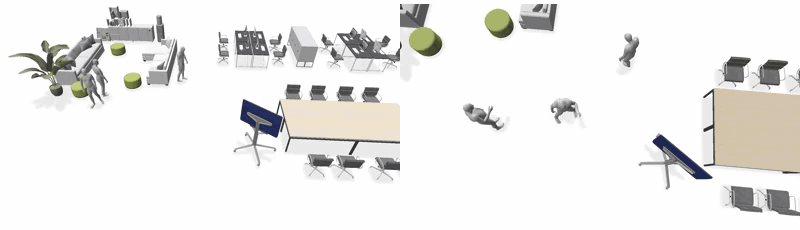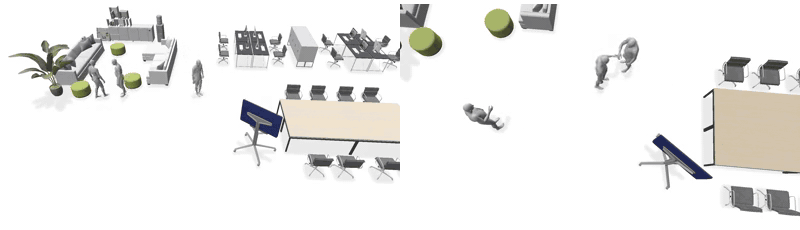
3 agents — Office

5 agents — House

5 agents — Restaurant

5 agents — Office
Video Presentation
Citation
@InProceedings{Li_2026_CVPR,
author = {Li, Lingxiao and Kim, Dongwon and Ruan, Lingyan and Chen, Bin and Kwon, Taesoo and Rhee, Taehyun},
title = {SyncMos: Scalable Motion Synchronisation for Multi-Agent Scene Interaction},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2026},
pages = {8174-8182}
}Acknowledgements
This work was supported by the Culture, Sports and Tourism R&D Program through the Korea Creative Content Agency grant funded by the Ministry of Culture, Sports and Tourism, South Korea (Project Number: RS-2024-00399136). This work was also supported by the Institute of Information and Communications Technology Planning and Evaluation (IITP) grant (No. RS-2020-II201373).